Demystifying Risk Analysis With Security Intelligence
Editor’s Note: Over the next several weeks, we’re sharing excerpts from the second edition of our popular book, "The Threat Intelligence Handbook: Moving Toward a Security Intelligence Program." Here, we’re looking at chapter seven, “Threat Intelligence for Risk Analysis.” To read the entire chapter, download your free copy of the handbook.
The National Institute of Standards and Technology (NIST) defines risk as a “measure of the extent to which an entity is threatened by a potential circumstance or event, and typically a function of: the adverse impacts that would arise if the circumstance or event occurs; and the likelihood of occurrence.”
Seems pretty straightforward, except ... Actually measuring risk is anything but. Think about it. Have you ever wanted to change career paths, make a big investment, move to a new city, or skydive out of a plane? Making the right decision requires thoughtful consideration — an understanding of potential benefits and consequences, and how to effectively balance them.
The same is true in business. There are myriad ways to analyze risk, making it challenging for organizations to pinpoint and implement effective models that objectively — and specifically — measure the probability of loss based on current threats. Without a solid measurement strategy in place, it's difficult to make confident decisions around resource allocation and future security investments.
Security intelligence can help overcome this hurdle by providing the insight necessary to gauge risk framework efficacy. It also provides the actionable context security leaders need to articulate specific probabilities of future loss — in dollars and cents — to their executive teams and boards. Clarity comes from specificity. Without specific loss probabilities, businesses can potentially waste resources on unnecessary controls, or worse, lack controls where they are needed most.
The following excerpt from "The Threat Intelligence Handbook: Moving Toward a Security Intelligence Program" has been edited and condensed for clarity. In it, we explore the value of risk models like the FAIR framework, examine the right and wrong ways to gather data about risk, and learn how intelligence can provide hard data about attack probabilities and costs.
The International Organization for Standardization (ISO) gives a sharper definition — risk is “the effect of uncertainty on objectives.” Risks are the chances of external factors and circumstances pushing us off course. What the ISO’s definition makes clear is that risks, and therefore risk management, are ultimately a matter of odds. They’re measurable and quantifiable. We just have to know what metrics to focus on, what tools we need to measure those metrics, and how to construct the right narrative to effectively communicate our findings to decision makers.
The problem is, people are generally not great at measuring risk. We have to battle through numerous cognitive biases that can cause us to poorly judge the likelihood of something happening, either by overestimating risks, causing us to act overly cautiously, or by barrelling ahead toward our goals without adequately considering the consequences of our actions. Defeating these impulses requires constructing an effective framework for action and reflection — one that you can follow consistently and improve over time.
The author Ray Bradbury once said that living at risk “is jumping off a cliff and building your wings on the way down.” To fairly represent Bradbury, it should be clarified that he said that within the context of encouraging people to take risks, arguing that you’ll never learn unless you try something and make mistakes along the way — the image of young birds leaping from their nests before knowing how to fly comes to mind. But even within the pretext of “nothing ventured, nothing gained,” one should perhaps not leap off cliffs without at least carrying the materials and blueprints one might need, should one indeed desire to build wings along the way rather than crashing into the ground.
In this chapter from our new book, “The Threat Intelligence Handbook,” we’ll explore the value of using models like the FAIR framework to get those materials and blueprints we need to manage risk well, see the right and wrong ways to gather data about risk, and learn how threat intelligence can provide hard data about attack probabilities and costs.
The following chapter has been edited and condensed for clarity.
Threat Intelligence for Risk Analysis
Today, there are more than 1,700 vendors in cybersecurity. Most of them define their mission as some version of “making your environment secure.” But how can enterprises set priorities for investing in technology and services, as well as people?
Risk modeling offers a way to objectively assess current risks, and to estimate clear and quantifiable outcomes from investments in cybersecurity. But many cyber risk models today suffer from either:
- Vague, non-quantified output, often in the form of “stoplight charts” that show green, yellow, and red threat levels
- Estimates about threat probabilities and costs that are hastily compiled, based on partial information, and riddled with unfounded assumptions
Non-quantified output is not very actionable, while models based on faulty input result in “garbage in-garbage out” scenarios, whose output appears to be precise but is in fact misleading.
To avoid these problems, enterprises need a well-designed risk model and plenty of valid, current information, including threat intelligence.
The FAIR Risk Model
The type of equation at the core of any risk model is: Likelihood of occurrence x impact.
But clearly God (or the Devil) is in the details. Fortunately, some smart people have developed some very good risk models and methodologies that you can use or adapt to your own needs. One that we like is the Factor Analysis of Information Risk (FAIR) model from the FAIR Institute.
The FAIR framework helps you create a quantitative risk assessment model that contains specific probabilities for loss from specific kinds of threats. The image below shows the framework of this model.
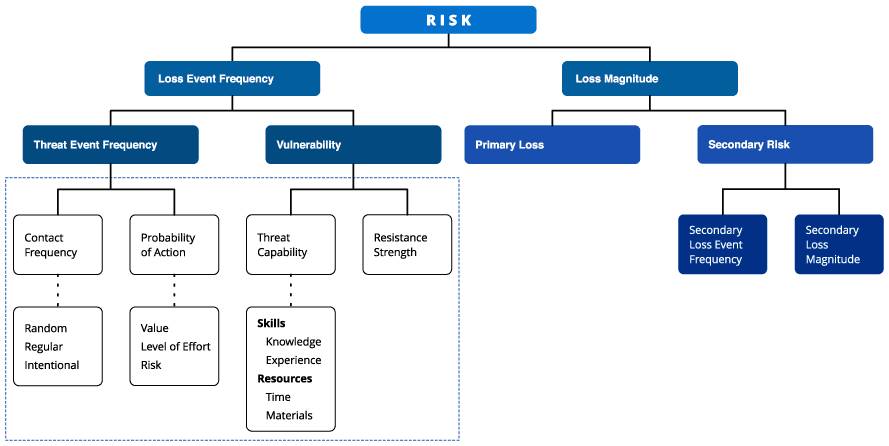
The FAIR framework, with elements informed by intelligence highlighted. (Source: The FAIR Institute)
Measurements and Transparency Are Key
The FAIR framework (and others like it) enable you to create risk models that:
- Make defined measurements of risk
- Are transparent about assumptions, variables, and outcomes
- Show specific loss probabilities in financial terms
When measurements, formulas, assumptions, variables, and outcomes are made transparent, they can be discussed, defended, and changed. Because much of the FAIR model is defined in business and financial terms, executives, line of business managers, and other stakeholders can learn to speak the same language and to classify assets, threats, and vulnerabilities in the same way.
Try to incorporate specific probabilities about future losses into your risk model whenever possible. Specific probabilities enable risk managers and senior executives to discuss the model and how it can be improved, after which they have more confidence in the model and the recommendations that come out of it.
In the table below, two pairs of statements sit next to each other. In each pair, which statement is more useful?
| “The threat from distributed denial of service (DDoS) attacks to our business has been changed from high to medium (red to yellow)." | “There is a 20 percent probability that our business will incur a loss of over $300,000 in the next 12 months because a distributed denial of service (DDoS) attack will disrupt the availability of our customer-facing websites.” |
| “The threat of ransomware to our business has changed from low to medium (green to yellow).” | “There is a 10 percent probability that our business will incur a loss of $150,000 in the next 12 months due to ransomware.” |
Threat Intelligence and Threat Probabilities
As shown in the left side of the FAIR framework in the image above, a big part of creating a threat model involves estimating the probability of successful attacks (or “loss event frequency,” in the language of the FAIR framework).
The first step is to create a list of threat categories that might affect the business. This list typically includes malware, phishing attacks, exploit kits, zero-day attacks, web application exploits, DDoS attacks, ransomware, and many other threats.
The next step is much more difficult: to estimate probabilities that the attacks will happen, and that they will succeed (e.g., the odds that the enterprise contains vulnerabilities related to the attacks and existing controls are not sufficient to stop them).
Try to avoid the following scenario: A GRC (governance, risk, and compliance) team member asks a security analyst, “What is the likelihood of our facing this particular attack?” The security analyst (who really can’t win) thinks for 30 seconds about past experience and current security controls and makes a wild guess: “I don’t know, maybe 20 percent.”
To avoid appearing clueless, your security team needs answers that are better informed than that one. Threat intelligence can help by answering questions such as:
- Which threat actors are using this attack, and do they target our industry?
- How often has this specific attack been observed recently by enterprises like ours?
- Is the trend up or down?
- Which vulnerabilities does this attack exploit (and are those vulnerabilities present in our enterprise)?
- What kind of damage — technical and financial — has this attack caused in enterprises like ours?
Analysts still need to know a great deal about the enterprise and its security defenses, but threat intelligence enriches their knowledge of attacks, the actors behind them, and their targets. It also provides hard data on the prevalence of the attacks.
Threat Intelligence and the Cost of Attacks
The other major component of the formulas in our model is the probable cost of successful attacks. Most of the data for estimating cost is likely to come from inside the enterprise. However, threat intelligence can provide useful reference points on topics like:
- The cost of similar attacks on enterprises of the same size and in the same industry
- The systems that need to be remediated after an attack, and the type of remediation they require
Get 'The Threat Intelligence Handbook'
This chapter is just one of many in our new book that provides helpful explanations of the different ways threat intelligence can be applied to your security program. Other chapters look at different use cases for threat intelligence, like how it can benefit vulnerability management, incident response, security leadership, and more.
And as far as this chapter goes, you’ll find more content in the book as well, including more charts and figures, like a timeline showing trends in the proliferation of malware families. Get your free copy of “The Threat Intelligence Handbook” now.
Related