The Recorded Future Intelligence Cloud
AI-driven Intelligence Cloud to identify and mitigate threats.


Too much data
Petabytes of data, millions of sources, and billions of connections
Too few resources
The cybersecurity talent gap was 3.4M, up 26% from previous year

More sophisticated attacks
Every 39 seconds, a new cyberattack happens
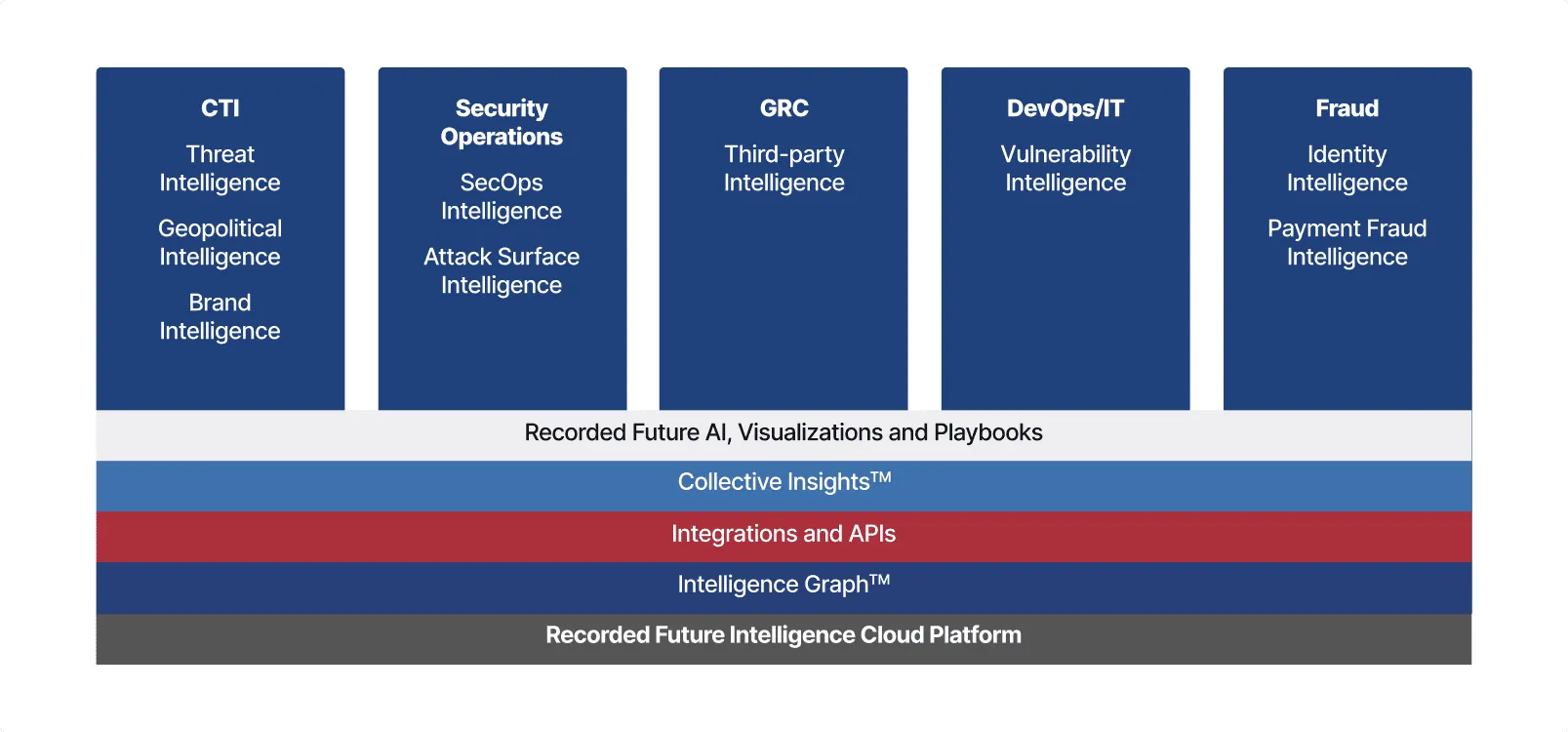
An intelligence platform is critical in the modern security stack but getting intelligence right is hard. You need the platform to be ...

Automated & real-time
Automate the collection, organization, and analysis of data at internet scale in real-time

Comprehensive
The world’s most comprehensive intelligence based on multiple sources including the dark web, open web, technical, and customer telemetry

Integrated & actionable
Integrate intelligence into the security workflows used today and in the future, to make it actionable for every team
A single platform to enable organization-wide decision making
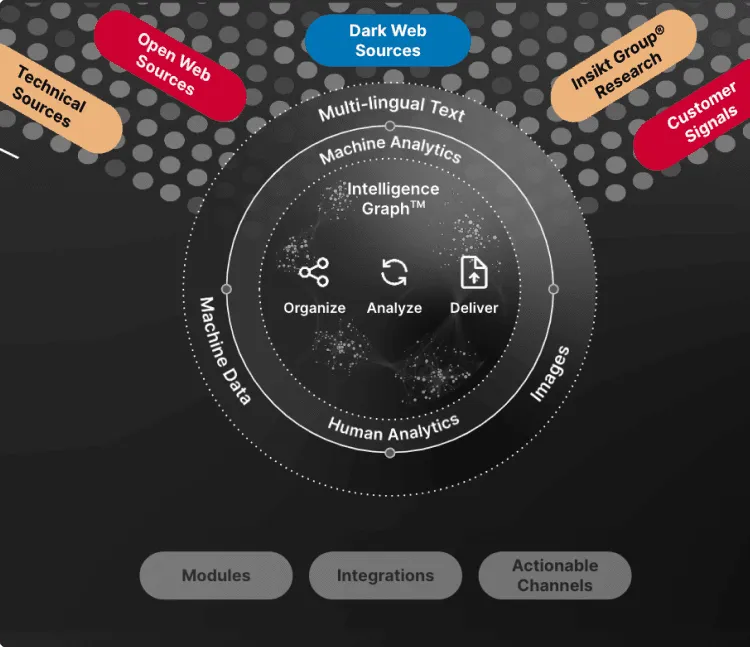
Intelligence Graph
Recorded Future’s Intelligence Graph has been collecting, structuring, analyzing, and turning large volumes of threat data into actionable insights from every corner of the internet for more than a decade. It automatically collects data across adversaries, their infrastructure, and targeted organizations. Data is dynamically linked and analyzed in real time - 24/7/365.
Integrations and API

Recorded Future’s APIs allow security teams to integrate intelligence exactly where they need it to power security workflows. With 100+ out-of-the-box Recorded Future integrations and key tools like SIEM, SOAR, ITSM and others, teams can quickly start with intelligence in their security stack.
Collective Insights
Collective Insights™ enables security teams to rise above the noise and connect the dots between the vast external threat environment, customers’ internal telemetry and Recorded Future’s global customer base. It powers our platform to drive increased visibility, improved detection and response and enables teams to take proactive action.
Recorded Future AI

Recorded Future AI automates the analysis and dissemination stage of the intelligence cycle to quickly mitigate threats. It powers analysts by automating time consuming manual tasks, reduces time to analyze and respond, and helps democratize the use of intelligence across multiple teams through natural language interface.
Visualizations & Playbooks
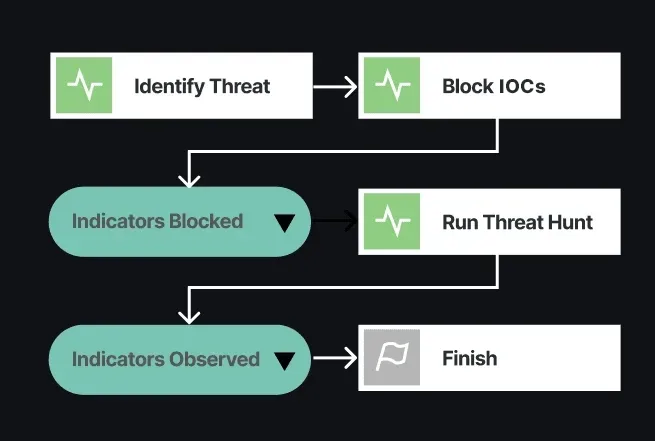
Visualizations from Recorded Future help security teams quickly analyze threat intelligence to understand how it impacts their organization. Playbooks make intelligence actionable natively in the Recorded Future Intelligence Cloud platform as well as within security tools used by your team.